MLP Benchmark
Source code for benchmark: https://github.com/r-xla/benchmarks/tree/main/benchmarks/mlp.
TODO:
Experiment Setup
The benchmark compares three implementations of an MLP training loop: PyTorch, R torch, and anvil (with both compiled loop and R loop variants). The task is a synthetic regression problem where random normal data is generated with a linear target plus noise.
The CPU benchmark was run with 32 threads.
CPU benchmark parameters:
Besides the parameters apparent from the plot, we used:
- Input features (p): 10
- Optimizer: SGD (lr = 0.0001)
- Loss: MSE
- Repetitions: 10
Timing excludes the warmup phase. For anvil, compilation time is recorded separately. All reported values are medians across replications.
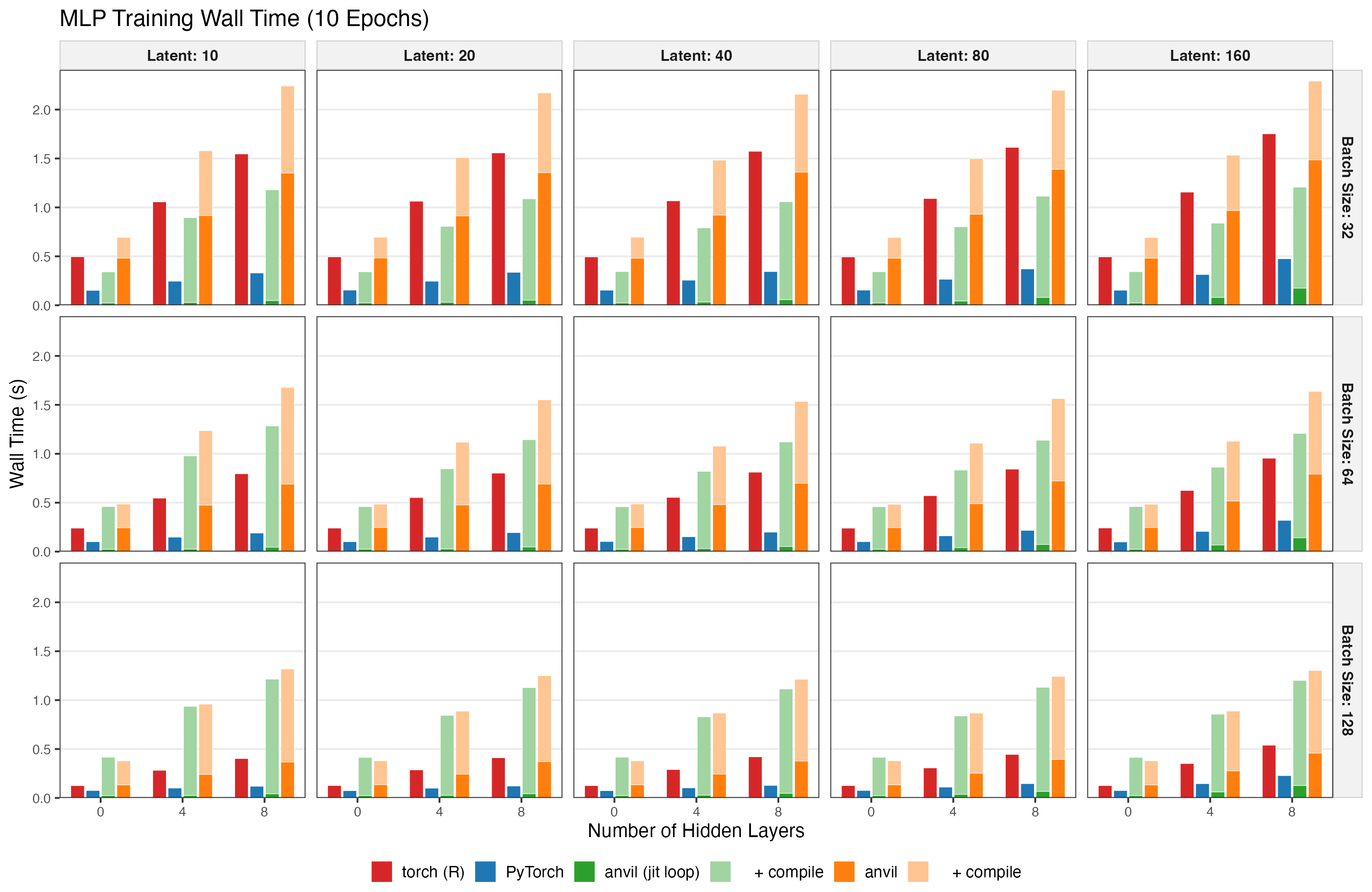
CPU Results
The barplot below shows wall time for 10 epochs of training, decomposed into runtime (solid color) and compilation overhead (lighter shade). Compilation only applies to the anvil variants; for torch and PyTorch it is zero.
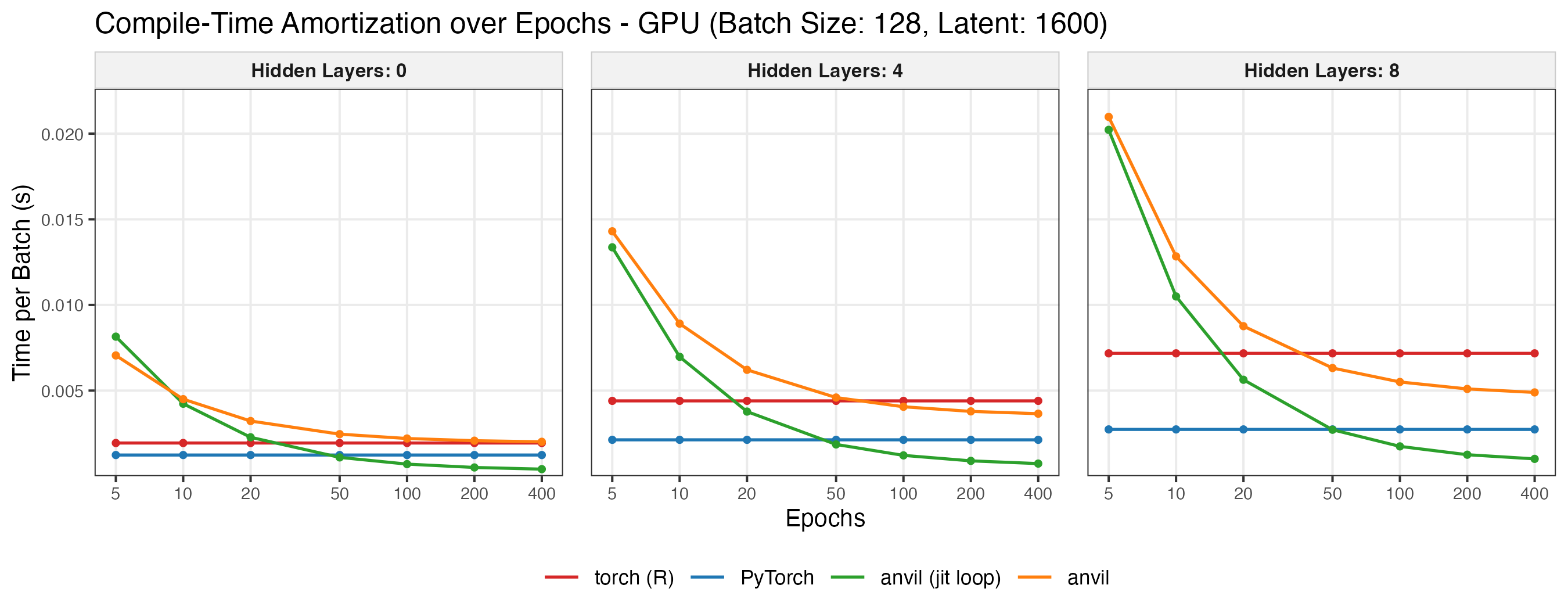
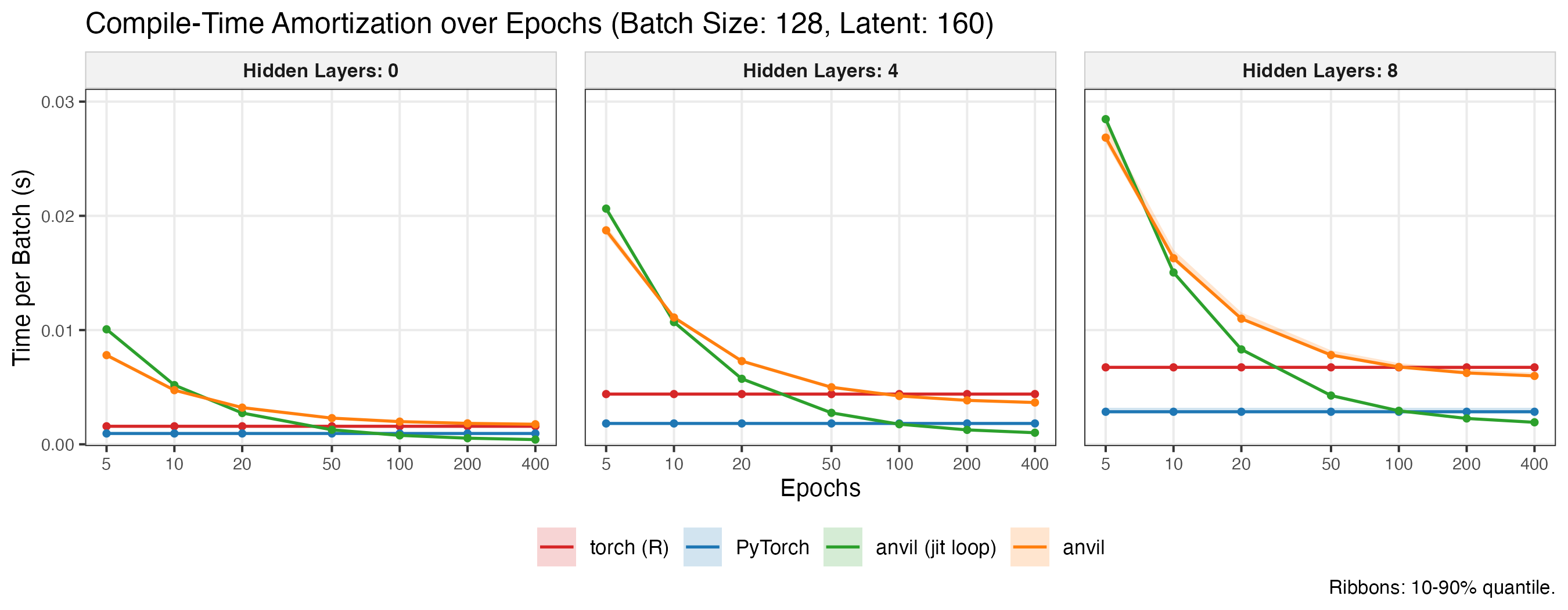
The amortization plot exemplarily shows the effective per-batch cost when increasing the number of epochs. Ribbons indicate the 10–90% quantile range across replications. As the number of epochs grows, the amortized cost of the anvil variants converges toward their pure runtime cost per batch.
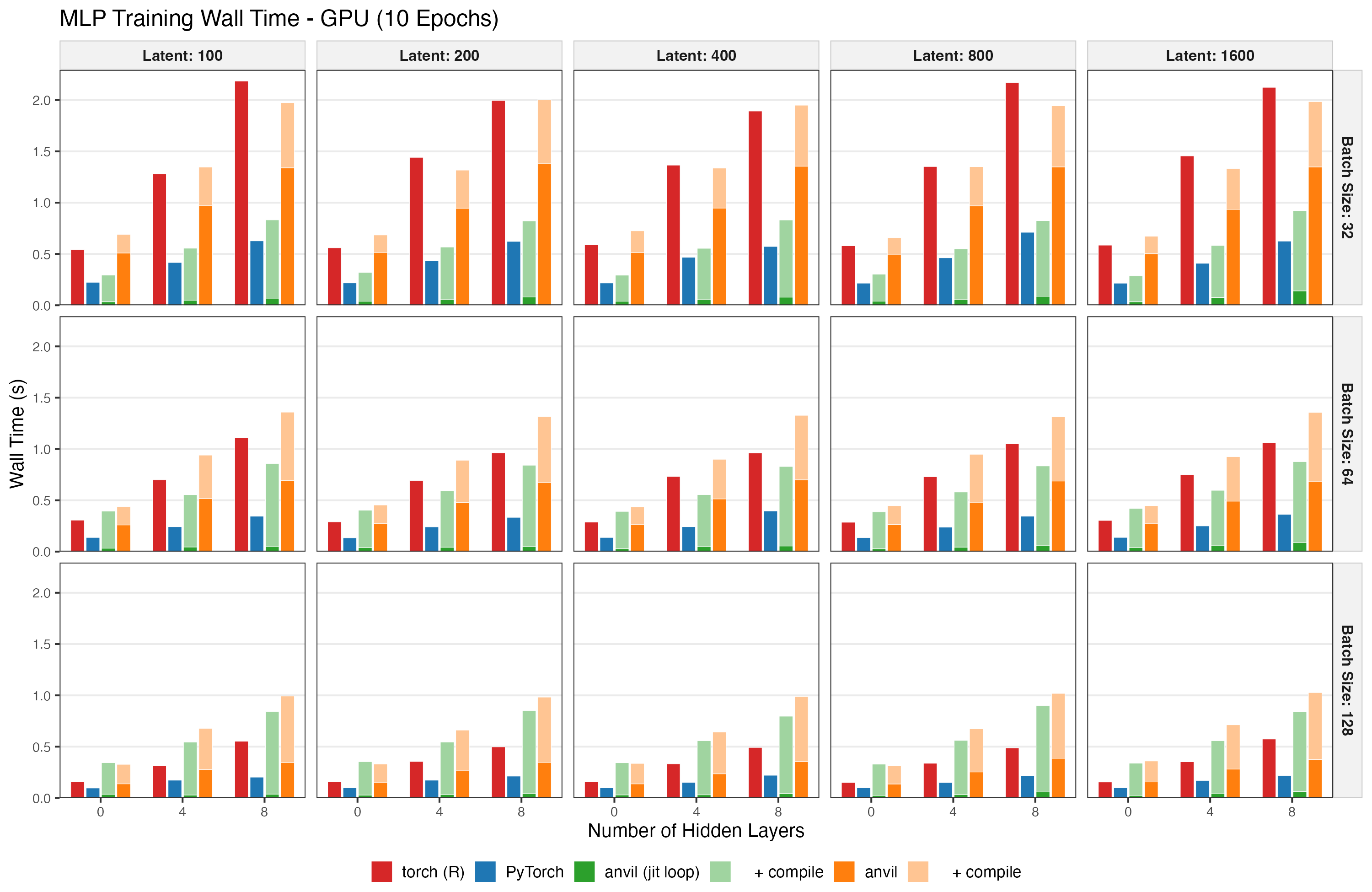
GPU Results
The GPU benchmark was run on hgx-h100-94x4 and uses the same setup but runs on CUDA with larger latent dimensions (10x). Note that only a single repetition was run, so no variability information is available.
Note that the anvil implementation is the only one that does not (yet) use asynchronous evaluation. Having async kernel dispatch will improve runtime performance in the future.
The amortization plot below exemplarily shows the effective per-batch cost.